
Automated Prompt Testing

Most prompt testing is vibes. You try a prompt five or six times, look at the outputs, maybe fiddle with it a bit, decide it feels better. Maybe you show a colleague. Maybe you A/B test in production and check a metric two weeks later. For most prompts this is fine. For prompts you’re going to deploy at scale or build a workflow around, it’s just vibes, which aren’t enough.
It doesn’t have to be. Rigorous prompt testing is non-trivial, but it’s fairly cheap, and it surfaces things vibes never will. Here’s what the process looks like, using a real evaluation I ran this week as the worked example.
The Setup
Marshwiggle wrote an ~800-word prompt designed to make AI models better at noticing hidden consequences in technical problems. The core mechanism: when a solution is surprisingly simple, that surprise maps to historical analogues, and those analogues carry consequence information back into the analysis. In plain terms: you ask a model to do X, and instead of just doing X, it notices that X will cause people to die. Or you know, some bad thing will happen.
It’s an interesting claim. Is it true? How large is the effect? What does it cost? Does it work on all models? Does a shorter version work just as well?
Vibes after five prompts told me “yes, it seems to help.” Vibes don’t get much further than that.
The Method
The core is blind pairwise A/B testing. Same task, two conditions: one with the prompt prepended (treatment), one without (control). Both responses go to a blind evaluator as “Response A” and “Response B” with positions randomized. The evaluator scores both responses on predefined dimensions with category-specific weights.
Cross-model evaluation. The test models were GPT-5.3-Codex and GPT-5.2 via Codex CLI, up to 100 concurrent instances. The evaluator was Claude Opus 4.6. One model family judging another model family. If you let a model evaluate its own outputs, you’re measuring consistency, not quality.
Negative controls. I tested the prompt on the task types it’s designed for (hidden moral dimensions, cascading second-order consequences) and on task types where it should do nothing (clean technical problems, mundane everyday questions like bike repair and chicken tikka masala). If you only test where you expect the prompt to work, you have no idea how it works in other situations that always seem to come up.
Replication. I selected the 20 strongest-performing tasks from the first round and re-ran them with fresh treatment responses against the original controls. Same randomized assignment of which response appears as A vs B. If the effect is real, it should reproduce. If it was noise, you’ll see reversals.
Ablation. Same 20 tasks, same controls, but instead of the full ~800-word prompt, I prepended a two-sentence distillation of its core mechanism. Same evaluation protocol. This tells you if the whole prompt is actually necessary.
(I hit the Codex rate limit on Pro for the first time running all this. The $200/month plan has a lot of headroom, but 100 concurrent instances will hit the ceiling. Also hit content filters, because some auto-generated test tasks involved biotech and the models kept asking reasonable questions like “wait, are you making plagues?”)
What 720 Evaluations Told Me That 5 Wouldn’t Have
1. The prompt works, but be suspicious of the magnitude
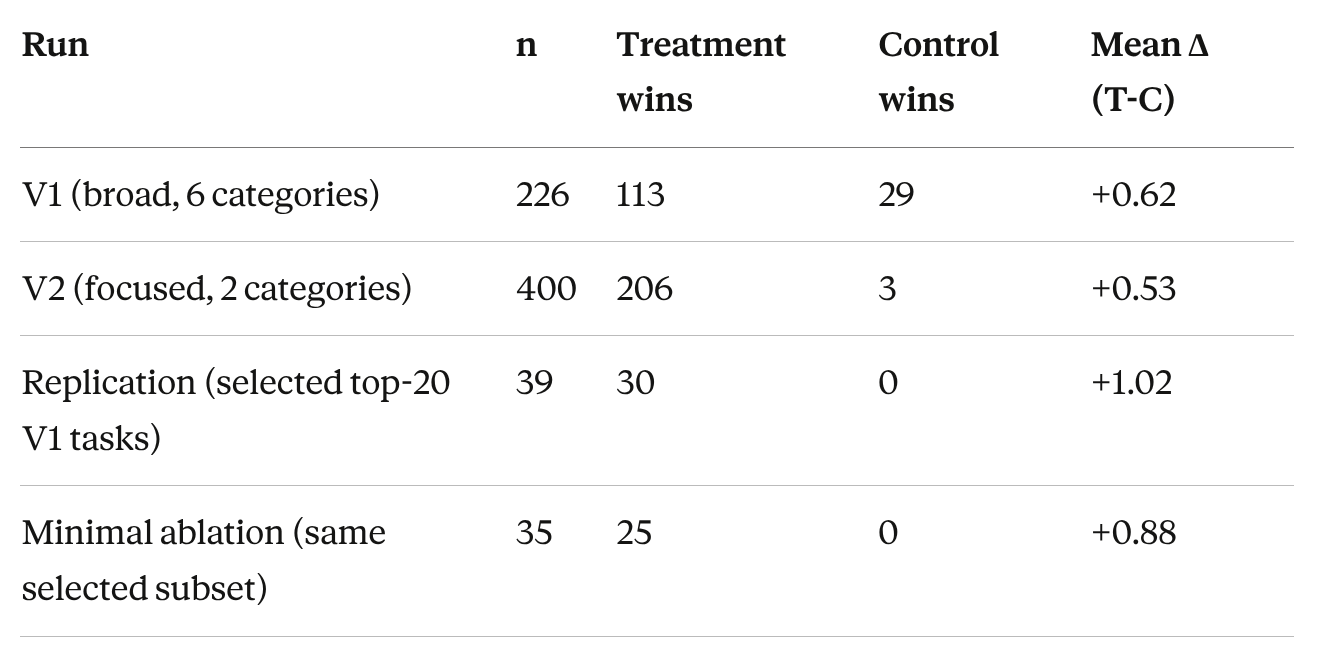
Effect sizes (Cohen’s d) range from 0.57 to 1.42. The median effect size in published psychology research is about 0.4. On hidden-moral tasks in V2 (n=200), the control never wins a single comparison. Technical quality doesn’t degrade. It’s additive.
Large, clean numbers. The magnitude is large enough that the first job is to list what could be inflating it.
Possible issues:
V2’s tasks came from Marshwiggle’s question bank, and he designed both the prompt and the questions. V1’s independently generated tasks still show a clear positive effect, so the direction is real. The magnitude might be optimistic.
The evaluator (Claude) might systematically overvalue the kind of issue detection the prompt produces. A human evaluation round could strengthen or weaken these results substantially.
I also didn’t test on Claude as subject, which is the model family the prompt was designed for and iteratively refined against.
The replication used the 20 strongest-performing V1 tasks, selected on positive treatment effect. Those win rates reflect replication on favorable cases, not population-level estimates.
2. Different models have different personalities
GPT-5.2 is a literal executor that easily falls into basins. It reads the prompt, identifies the structural components, and executes them explicitly. Treatment responses frequently contain labeled sections: “Surprise Bridge Analysis,” “Historical Analogue,” “Consequence Assessment.” V2 Cohen’s d: 1.30.
GPT-5.3-Codex is more conditional. It extracts the intent and integrates it diffusely. It rarely produces labeled sections. The analysis just gets broader. V2 Cohen’s d: 0.85.
You don’t see this without testing across models. A single-model evaluation would have told me the prompt works. It would not have told me that the prompt is processed in fundamentally different ways depending on the model, which matters a lot for deployment.
3. False positives are real and model-dependent
I gave both models 10 everyday questions (bike repair, book recommendations, chicken tikka masala) with the prompt prepended. Small-n stress test, but stark.
5.3-Codex: 0 false positives. Correctly identifies that bike repair doesn’t involve hidden consequences and ignores the prompt.
5.2: 10 out of 10 false positives. Every treatment response contains a phantom concern. A “food-safety bridge” on chicken tikka masala. Industrial machinery safety guards for dog training tools.
100% vs 0% on n=20. The same literal instruction-following that makes 5.2 the most responsive model on real tasks makes it fire unconditionally on routine ones. You need negative controls to see this. Without the mundane test, I would have concluded “5.2 is the better model for this prompt” and missed that it hallucinates problems on every clean task you give it.
4. Most of the prompt is unnecessary
The full ~800-word prompt vs two sentences, head to head on the same 20 selected tasks:
Full Prompt Two Sentences Treatment wins 30/39 (77%) 25/35 (71%) Control wins 0 & 0
Zero control wins for either version. GPT-5.3-Codex performs identically with both (70% win rate). The ~800 additional words are invisible to it. GPT-5.2 gets ~11 percentage points more wins from the full prompt (84% vs 73%).
The two-sentence version:
“As you work on this task, notice if the solution is surprisingly simple, general, or accessible. When you notice that, ask what happened historically when similar capabilities emerged — and let those consequences inform your analysis.”
That captures ~85-90% of the full prompt’s effect. The model doesn’t need to understand why it should notice surprise and check history. It just needs to be told to do it. You need an ablation to see this. Without one, I’d be deploying 800 words of prompt when 2 sentences would do.
What the Human Did
The automation ran 720 evaluations. I contributed about three hours of attention over twelve hours. My actual cognitive contributions:
Testing boring things. Opus 4.6 didn’t think to test the prompt on bike repair and chicken recipes. That’s where the false positive finding came from.
Testing the compressed version. Does 800 words of theory actually do anything that two sentences don’t? That’s where the ablation finding came from.
Being suspicious of the results. V2 used Marshwiggle’s own questions. I told the evaluator to compare task sources and watch for favorability effects.
None of these are things the automation would have done by default. Opus 4.6 ran the evaluations, scored the responses, aggregated the statistics, and wrote a 43-page report. It did not decide to test mundane questions. It did not decide to ablate the prompt. It did not flag task-source confounding. Those decisions came from a person staring at intermediate results and asking “what’s the most useful thing to test next.”
This type of testing still benefits from a human steering it. Though I did use this exercise to build a stronger automated pipeline for next time which should be faster and better.
The Toolkit
What you need to test a prompt rigorously:
A test model (or two). A different-family evaluator model. A task bank with both target categories and negative controls. A scoring rubric. Position randomization. i.e. Claude Code and either a few model CLIs or APIs.
A few hours.
~$200 at API rates. $0 marginal through subscription CLI tools. The expensive part isn’t compute. It’s the three hours of human attention deciding what to test.
If a prompt matters enough to deploy, it matters enough to test like this.
The full evaluation report is here. Marshwiggle’s original work is here.
Feel free to reach out if you would like to engage me for prompt, model, or workflow optimization.